

Amazon Relational Database Service (RDS) is a fully managed relational database service that simplifies database management tasks like provisioning, scaling, and patching.
Here are the key features and capabilities of AWS RDS explained in a clear and approachable manner:
Key Points:
1. Managed Database Service
- AWS RDS is a fully managed relational database service. This means it handles the heavy lifting of database administration, such as provisioning, patching, backups, and recovery.
2. Supports Multiple Database Engines
- AWS RDS supports several popular database engines, including:
- PostgreSQL
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- IBM DB2
- Amazon Aurora
3. Automated Maintenance
- RDS provides automated provisioning, patching, and continuous backups. This ensures your database remains up-to-date and secure without manual intervention.
4. EBS-Backed Storage
- Data in RDS is backed by Amazon Elastic Block Store (EBS), which provides reliable and scalable storage for your databases.
5. Auto-Scaling Storage
- RDS automatically scales your database’s storage size needed. This ensures your database has the capacity it requires during peak usage without downtime.
6. Multi-AZ Deployments
- RDS supports Multi-AZ (Availability Zone) deployments, which enhance fault tolerance and high availability. In an outage, failover occurs seamlessly to a standby instance in another AZ.
Read Replicas
Read replicas are secondary copies of your primary database, designed to handle read-only queries. They are kept up to date with the primary database via asynchronous replication.
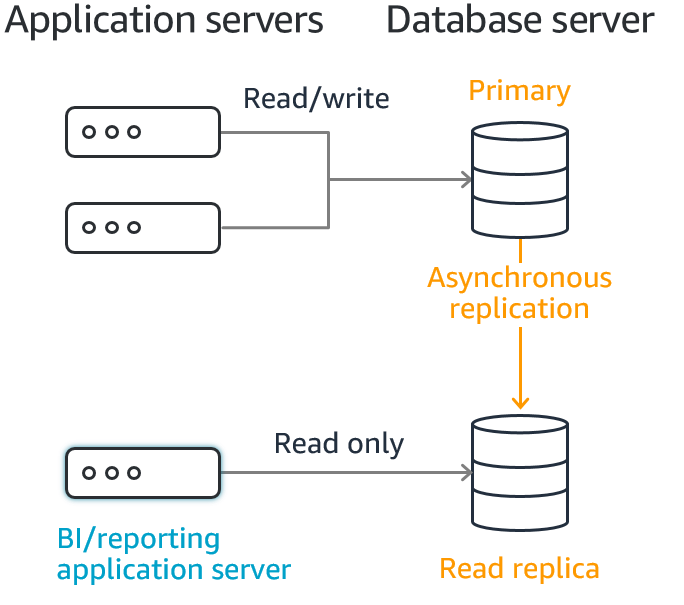
Key Points:
1. Offload Read Requests
- Read replicas allow you to offload read requests from the primary database, improving overall application performance.
2. Support for Up to 15 Read Replicas
- RDS supports up to 15 read replicas, making it highly scalable for read-intensive workloads.
3. Asynchronous Data Syncing
- Data is synced asynchronously to the read replicas, ensuring the primary database’s write operations remain unaffected.
4. Regional Replication
- Read replicas within the same region do not incur network fees, while cross-region replicas may have additional costs.
Read Replicas Flow:
1. Start
|
v
2. Offload read requests to improve application performance.
|
v
3. Add read replicas as needed:
- Up to 15 read replicas supported.
|
v
4. Data synchronization:
- Asynchronous syncing ensures the primary database's write operations remain unaffected.
|
v
5. Regional or cross-regional replication:
- Same region: No additional network fees.
- Cross-region: Data transfer fees may apply.
|
v
6. End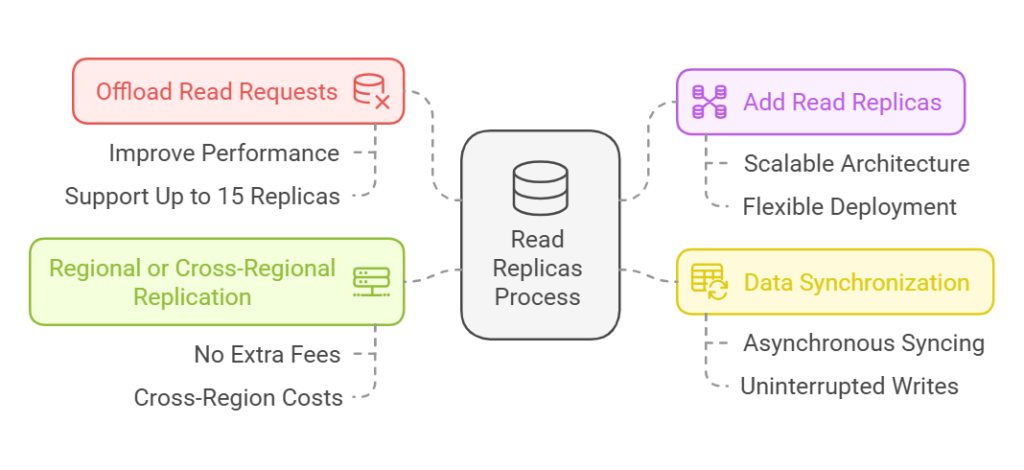
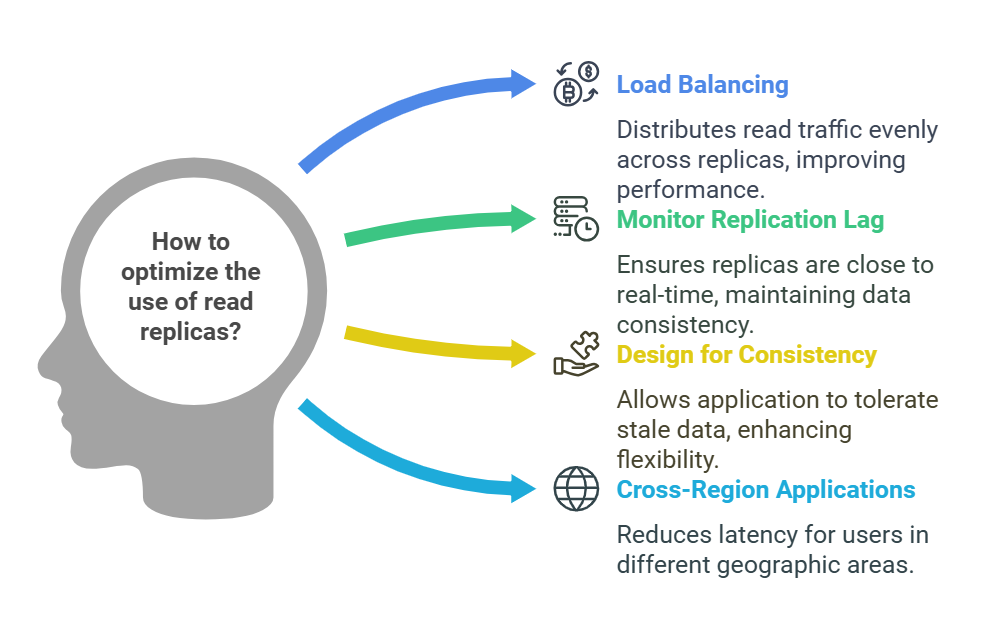
Best Practices for Using Read Replicas:
- Load Balancing: Use a load balancer to distribute read traffic evenly across all replicas.
- Monitoring Replication Lag: Regularly monitor the replication lag to ensure read replicas remain close to real-time.
- Design for Read Consistency: Ensure your application can tolerate slightly stale data if replication lag occurs.
- Cross-Region Applications: Use cross-region replicas to serve users in different geographic areas for better latency.
ReplicaLag:
- ReplicaLag is a key metric in AWS RDS that measures the time delay between the primary database and its Read Replica.
- This metric is particularly important because replication in RDS Read Replicas is asynchronous, meaning that updates to the primary database might not immediately reflect in the replica.
When your application uses Read Replicas, it’s important to know that they may not always have the most up-to-date information from the main database. This happens because there’s a small delay (replication lag) in copying changes from the main database to the replicas.
To handle this, you should design your application to be okay with slightly old information for certain types of data.
For example:
What works well:
- Product search results: A few seconds’ delay won’t significantly affect the user’s experience.
- User recommendations: Users won’t notice minor delays in seeing personalized suggestions.
- Public-facing data: Content like blog posts or FAQs that don’t require real-time updates can safely be served from replicas.
What doesn’t work well:
- Stock availability checks: Showing outdated inventory can result in a poor user experience (e.g., selling out-of-stock items).
- Payment verification: Transactions rely on real-time data for accuracy and security, so these should query the main database.
Simple Analogy: Live Sports Broadcast
- Read Replica: Think of watching a live sports game in a city that gets the broadcast slightly delayed. You still see the game, but the action is a few seconds behind in real time.
- Main Database: It’s like being at the stadium or watching the game live on TV. You get the most up-to-date and real-time view of the game.
Scenario: High-Performance Read Operations with Read Replicas
Use Case: An e-commerce application experiences high traffic during sales events like Black Friday.
Problem: The primary database becomes a bottleneck due to a surge in read operations like product searches, reviews, and inventory checks.
Solution: Create multiple Read Replicas of the primary database in different AWS regions or within the same region.
How It Helps:
- Distributes read traffic across replicas, reducing the load on the primary database.
- Improves query performance by allowing replicas to handle read-intensive workloads.
- Ensures a smooth customer experience, even during high traffic.
Implementation: Configure the application’s read queries to route to Read Replicas using connection pool settings or load balancers.
Standby Databases
Standby databases are critical in ensuring high availability and disaster recovery for modern applications. They act as backup systems, ready to take over if the primary database becomes unavailable.
Key Points:
- Deployment in Different Availability Zones (AZs):
- Standby databases can be deployed in a different AZ (Availability Zone), and changes are synced synchronously to ensure consistency.
- The synchronous data replication guarantees that the standby database has an up-to-date copy of the primary database’s data.
2. Automatic Failover Mechanism:
- If the primary database fails, the DNS entry automatically updates to redirect traffic to the standby database, ensuring minimal disruption.
- This process is seamless to end-users and helps maintain application availability.
3. Improved Disaster Recovery:
- Standby databases provide a robust disaster recovery solution.
- They protect against data center-level failures by maintaining a consistent copy in a separate AZ.
4. Read-Only Access (Optional):
- In some setups, standby databases can also be configured for read-only access, allowing them to handle read-heavy workloads when fail over isn’t required.

Standby Databases Flow:
1. Start
|
v
2. Deploy standby databases in a different AZ (Availability Zone).
|
v
3. Data synchronization:
- Synchronous syncing ensures consistency between primary and standby databases.
|
v
4. Automatic failover mechanism:
- If primary database fails:
- DNS entry redirects traffic to the standby database.
- If no failure: Continue normal operations.
|
v
5. End")
Use Cases for Standby Databases:
- Mission-critical applications where downtime is unacceptable.
- Systems requiring 99.99% or higher availability guarantees.
- Applications in industries with strict compliance and data retention requirements, such as finance or healthcare.
Scenario: Disaster Recovery with Multi-AZ Standby Database
Use Case: A financial services company needs high availability for its transaction database.
Problem: Database downtime could lead to significant revenue loss and regulatory penalties.
Solution: Enable multi-AZ deployment for the RDS instance, automatically creating a synchronous standby database in a different Availability Zone (AZ).
How It Helps:
- Provides automatic failover if the primary database becomes unavailable due to hardware failure, network issues, or maintenance.
- Ensures zero data loss with synchronous replication.
- Requires no manual intervention to restore database availability.
Example Scenario: During a power outage in one AZ, the database automatically fails over to the standby in another AZ, maintaining service continuity.
Conclusion:
AWS RDS simplifies database management and ensures high performance, availability, and reliability. With features like automated maintenance, support for multiple database engines, auto-scaling, multi-AZ deployments, and read replicas, it is an excellent choice for modern, scalable applications.
Your Thoughts Matter!
I’d love to hear what you think about this article — feel free to share your opinions in the comments below (or above, depending on your device!). If you found this helpful or enjoyable, a clap, a comment, or even a highlight of your favorite sections would mean a lot.
For more insights into the world of technology and data, visit subbutechops.com. There’s plenty of exciting content waiting for you to explore!
Thank you for reading, and happy learning! 🚀